Table of Contents
- Introduction
- Academia and Research
- Tutoring and Content Development
- Coding and Data Science
- My journey at the Office for National Statistics
- My journey at Quantexa
Introduction
Hello, I’m Dr. Usman Kayani — a Senior Data Engineer and Scientist with a solid academic foundation in Mathematics, showcased through my MSci and PhD degrees. My career is rooted in data engineering, data science, and theoretical physics, where I specialize in creating scalable data solutions, deploying machine learning models, and leveraging big data to solve complex, industry-wide challenges.

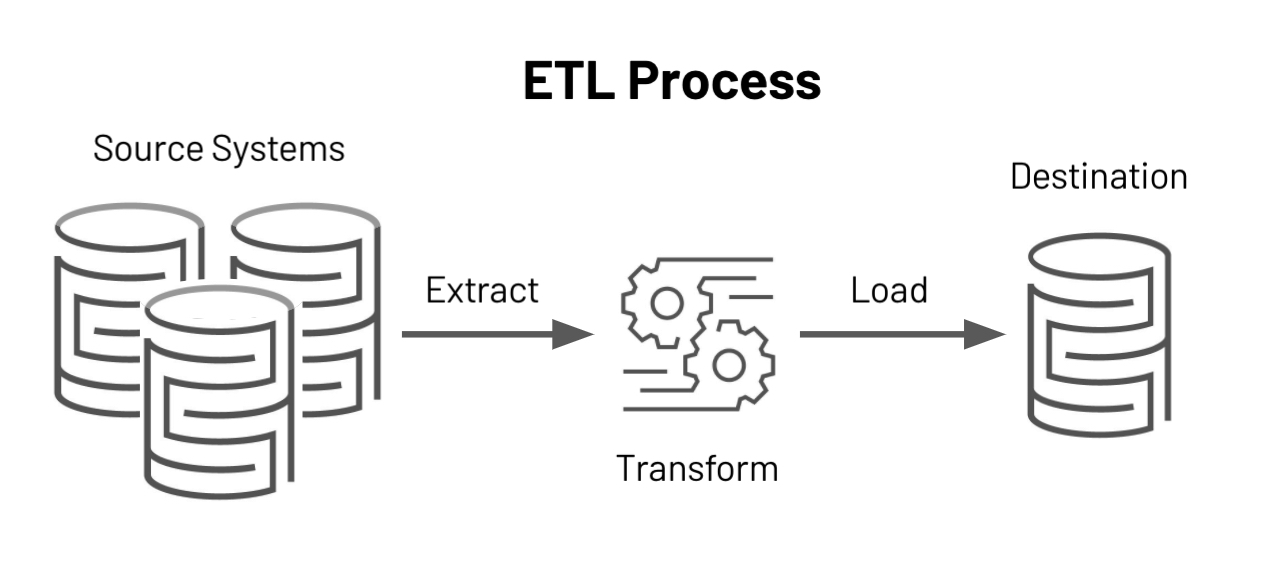
With over a decade of experience in Python development, enhanced by recent proficiency in Scala, I design and implement robust analytical data pipelines (ETL, RAP) and deploy machine learning models at scale. My technical expertise includes Apache Spark, Airflow, BigQuery, and SQL, enabling me to build dynamic, high-performance data solutions. Proficient in cloud platforms such as GCP, Cloudera, and AWS, I leverage cloud-based infrastructures to transform vast datasets into actionable insights, empowering businesses to make data-driven decisions with confidence.

As a neurodivergent individual with ADHD and Dyslexia, I bring a unique approach to problem-solving and innovation in data engineering. My neurodivergent perspective has fostered creativity and resilience, driving me to develop inventive solutions. As an advocate for diversity and inclusion, I am committed to fostering an environment where neurodiversity is understood and celebrated within the workplace.
In addition to my technical expertise, I am deeply committed to education and have taught Mathematics and Physics across various levels, from GCSE to advanced university topics, including statistics, linear algebra, and Python programming. My approach to teaching emphasizes accessibility, making complex topics understandable and engaging. I have also worked as a freelance mathematics content writer and video developer, producing educational materials for platforms reaching a wide audience.

Driven by a steadfast belief in the power of data and technology, I aim to use my skills for positive societal impact. I am always seeking innovative ways to apply data science to improve lives and drive meaningful change. Whether it’s mentoring new engineers, enhancing data engineering practices, or advocating for inclusivity, I am dedicated to harnessing the transformative potential of data to make a lasting difference.
Academia and Research
I completed an MSci in Mathematics, with First Class Honours, and a PhD in Applied Mathematics and Theoretical Physics at King’s College London.

During my MSci, I scored highly in my modules, most notably gaining 99% in linear algebra and partial differential equations with complex variables. Other pure and applied mathematics modules that I completed included topics covering advanced calculus, dynamical systems, probability and statistics, discrete mathematics, logic, complex analysis, manifolds, linear algebra, differential geometry and mathematical biology.

In my second year as an undergraduate, I had written a paper under the advice of one of my professors, who thought that it was interesting enough to be posted on the university website for the mathematics department. This gave me valuable experience on how to write a paper and investigate different mathematical techniques and ideas.
The paper I wrote was on a new method to solve linear ordinary differential equations of any order with non-constant coefficients and certain classes of partial differential equations. As a result, by the recommendation of another professor and based on my academic record, I was able to attend the fourth year module, Fourier analysis, for extra credit in my second year.
In the final two years of my MSci, I also completed modules in physics, covering quantum mechanics, advanced quantum field theory, statistical mechanics, advanced general relativity, string theory, and cosmology.
For my MSci dissertation, I studied integrable quantum spin chains. This introduced me to quantum interaction models particularly the Heisenberg spin chain, which describes the nearest neighbour interaction of particles with spin-$\frac{1}{2}$ (i.e electrons) and naturally arises in the study of ferromagnetism.
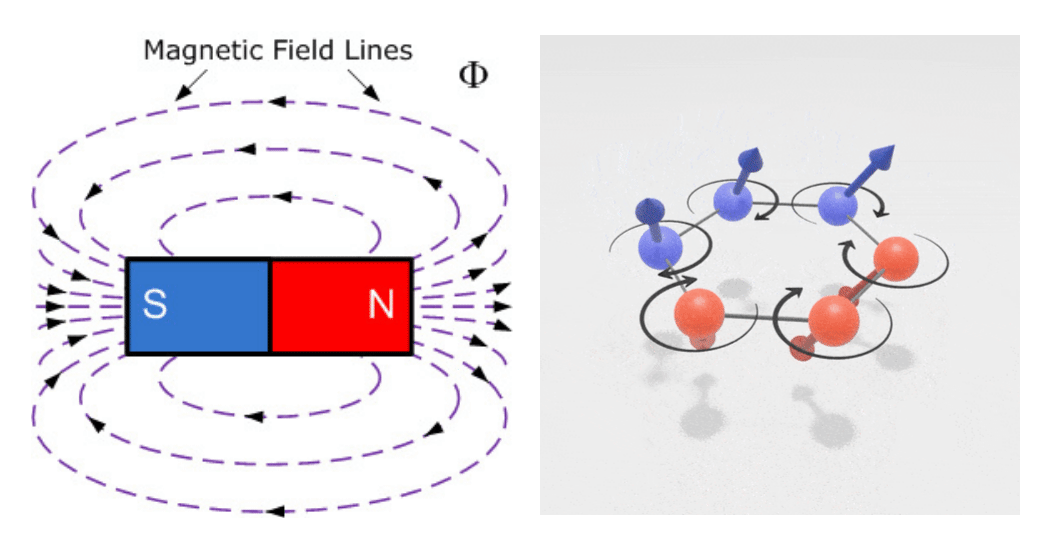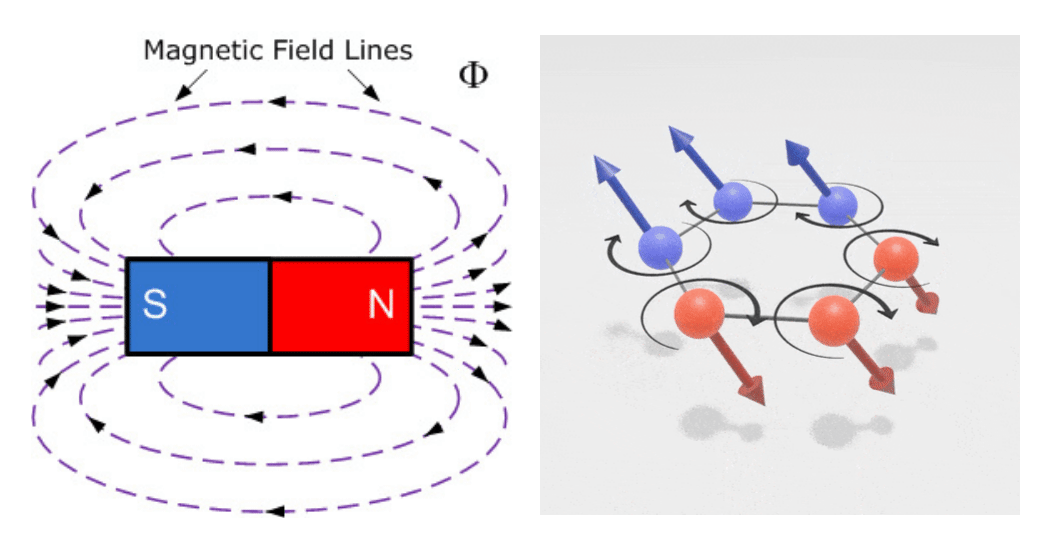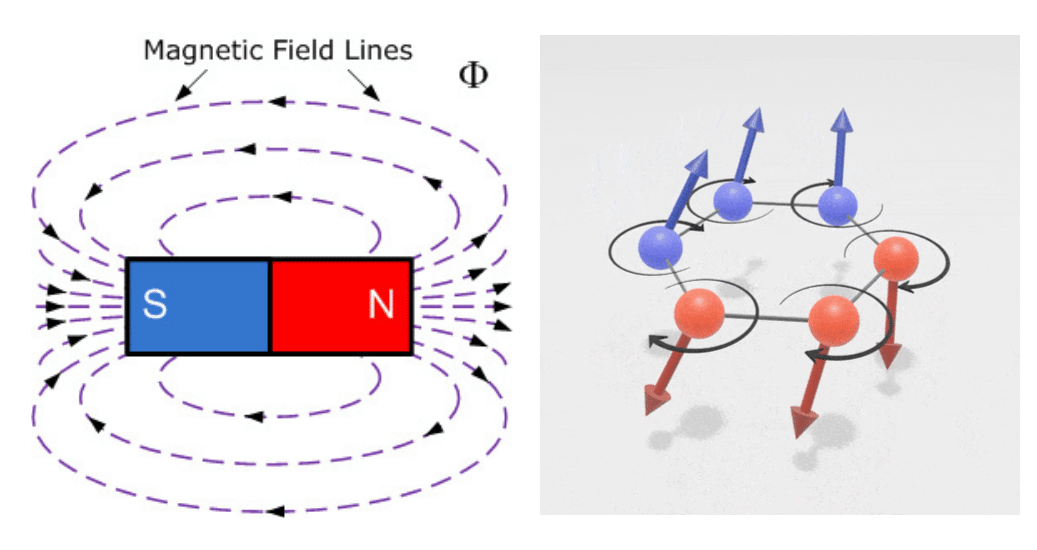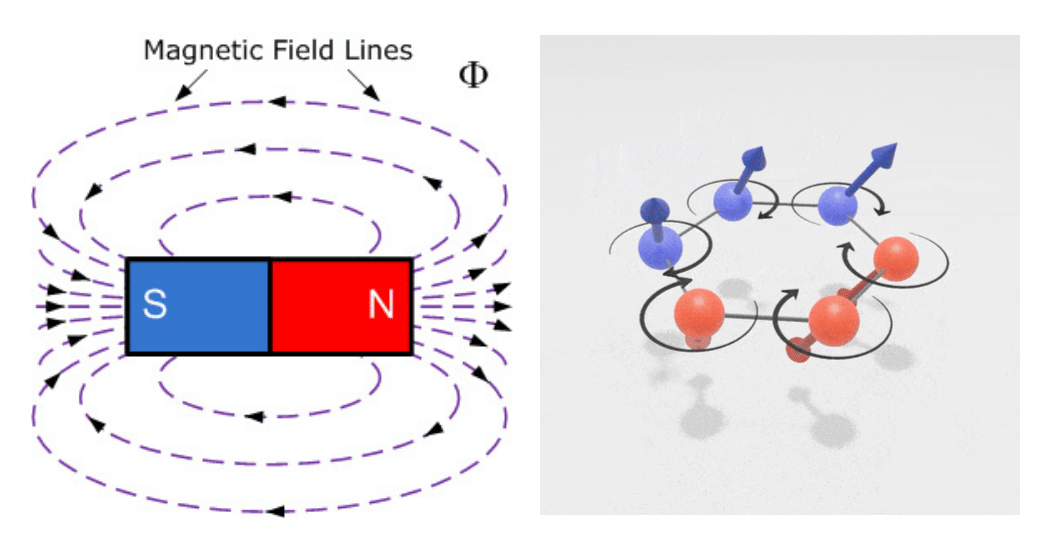
These models have acquired growing importance in quantum computing within the field of quantum information processing, mainly as a means of efficiently transferring information. In addition to the understanding of quantum computing that I acquired from the research, it also gave me insights into various mathematical methods to diagonalize large square matrices which can grow exponentially according to the number of particles.

For my academic excellence in my MSci, I was also awarded a scholarship by the Science and Technology Facilities Council (STFC) to undertake a PhD in Applied Mathematics and Theoretical Physics under the mathematics department. My research was in quantum gravity, which is the study of the relationship between quantum mechanics and general relativity.
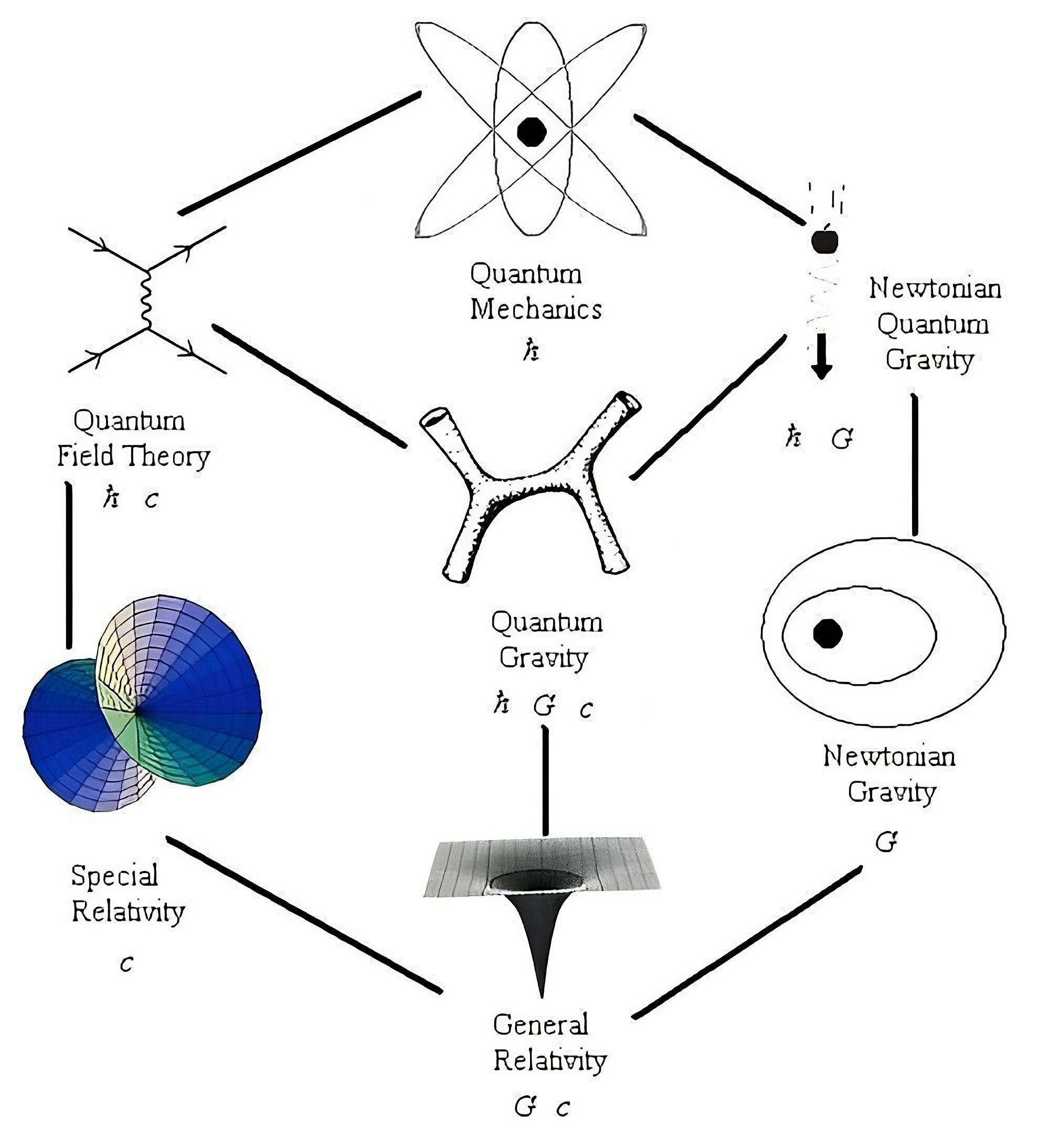
In particular, I studied string and supergravity theories, specifically type IIA, massive type IIA and 5-dimensional (both gauged and ungauged).
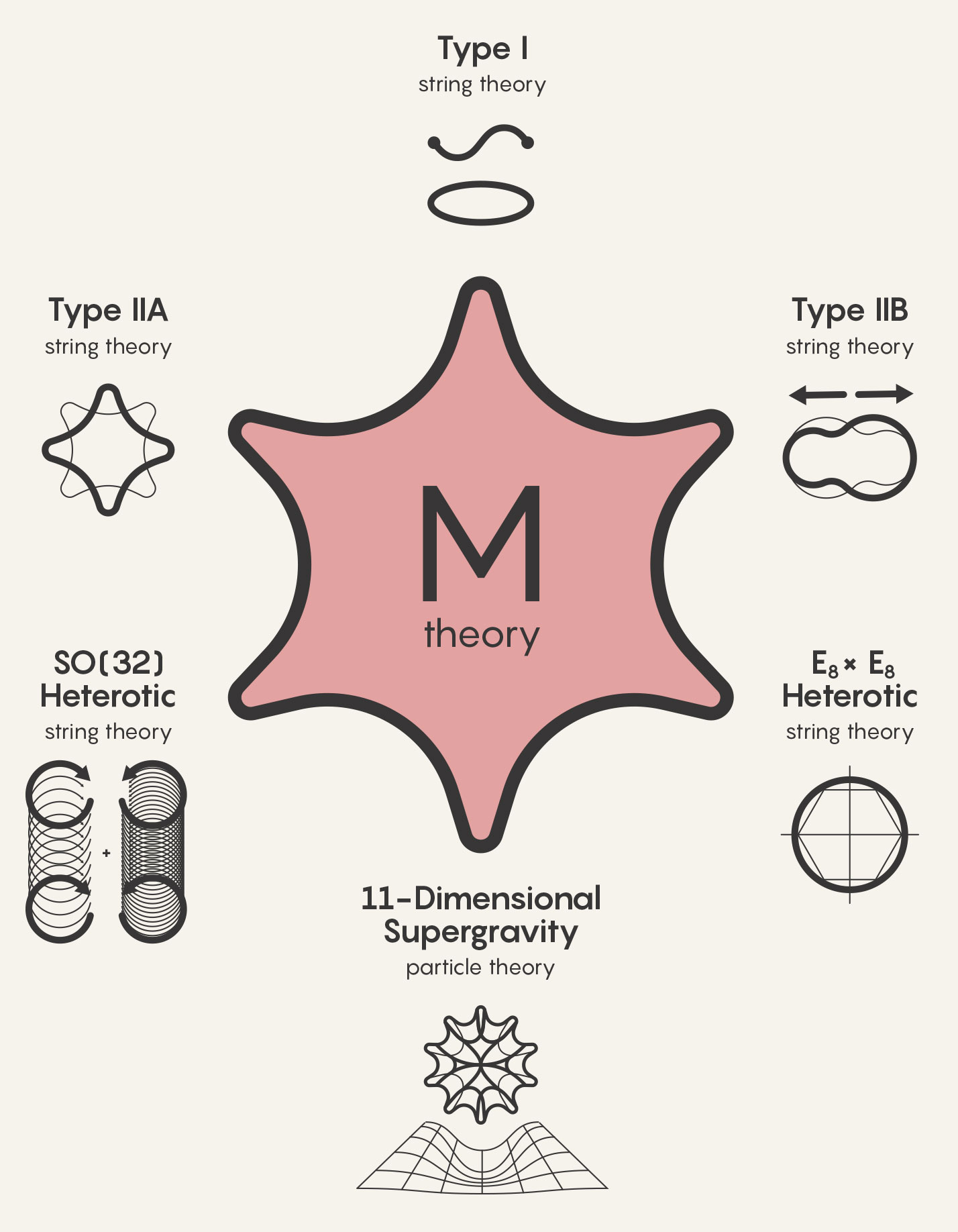
The main theme of my PhD research was a study of the symmetries of black hole horizons in quantum gravity.


The work has been published in three peer-review papers in leading international journals with the third publication on the five-dimensional supergravity theories being a sole-author paper. My examiners remarked at the great achievement to produce such a sole-author paper during a PhD. I had also continued my research and publications in quantum gravity as an independent researcher for black holes in 6-dimensional gauged $N=(1,0)$ supergravity.

The methodology used to investigate these problems involves techniques in Lie algebras, differential geometry, differential equations on compact manifolds, general relativity, supersymmetry and string theory. Algebraic and differential topology were also essential in the analysis.
For my research in quantum gravity, I also performed extensive computations on multi-dimensional arrays for supergravity calculations using Python with Cadabra, particularly for Clifford algebras and spinors in higher dimensions.

I also attended various academic seminars and conferences such as the Winter School on Supergravity, Strings, and Gauge Theory at CERN in Switzerland, and I presented my research at many conferences including the Young Theorists’ Forum at Durham University.

Tutoring and Content Development
I have experience teaching and tutoring Mathematics, Physics and Programming at a Graduate (BSc/MSc), A-level and GCSE. I was a graduate teaching assistant at King’s College London for 6 years, and a private tutor for over 12 years. During my PhD, I also volunteered for roles in science communication, such as with the Institute of Physics, to explain my research on black holes to school children.

In the last few years, I have also undertaken freelance work with Witherow Brooke, a private tuition and educational consultancy company which was featured in The Telegraph. I am currently tutoring university students in mathematics topics such as advanced statistics, linear algebra and Python coding.


I also worked as a freelance mathematics content writer and video developer for Nagwa, a leading educational technology company in the Middle East and North Africa. I was responsible for developing educational videos and content for the company’s online platform for topics in mathematics from GCSE to graduate level, such as algebra, trigonometry, calculus and statistics.

Coding and Data Science
I have extensive experience coding in many high-level programming languages (e.g C++, Java), scripting languages (e.g Python, R, Bash, etc) and symbolic languages (e.g Mathematica, MATLAB, Maple etc) using various operating systems (e.g Linux, Windows, Mac OS).
In addition to Cadabra, I used Mathematica and Maple for my research in quantum gravity during my PhD and beyond. I have also used various programming languages or libraries (e.g NumPy, SciPy, Matplotlib etc) to perform mathematical, physical, and statistical computations for various analyses and datasets.

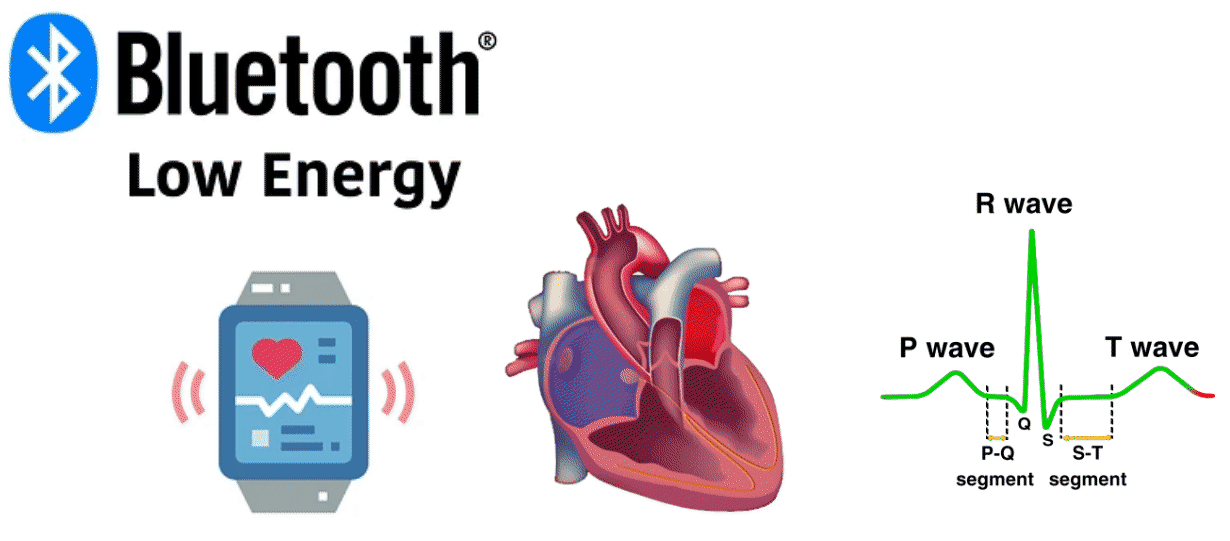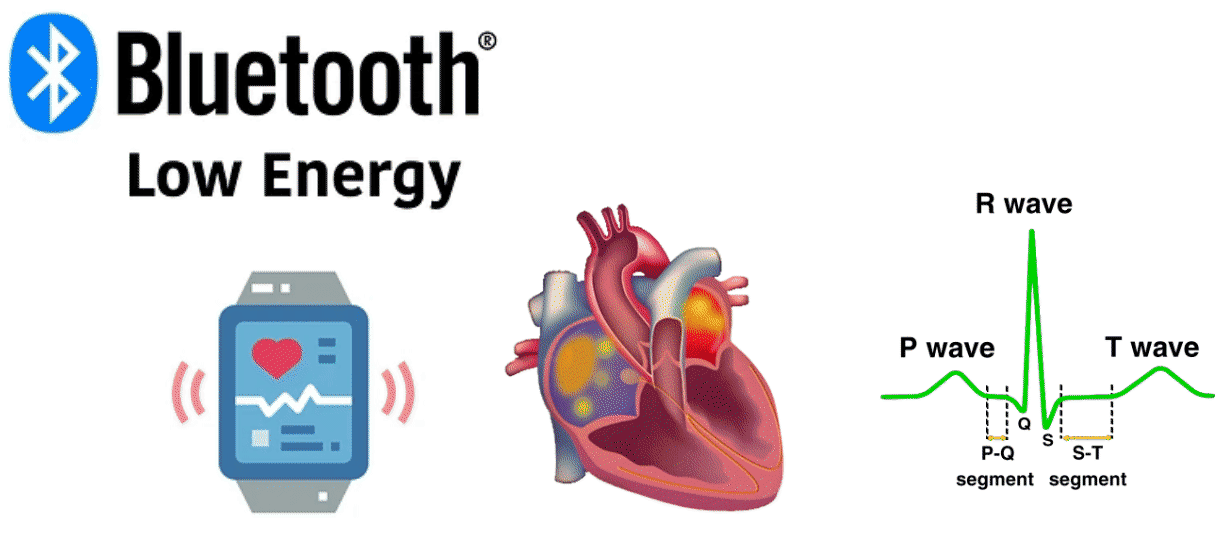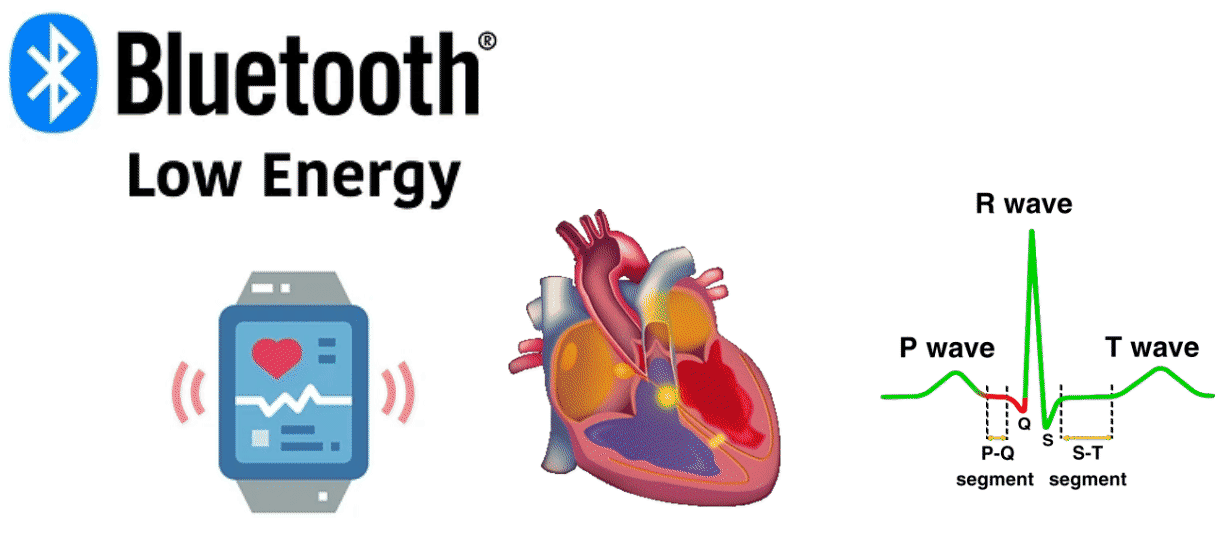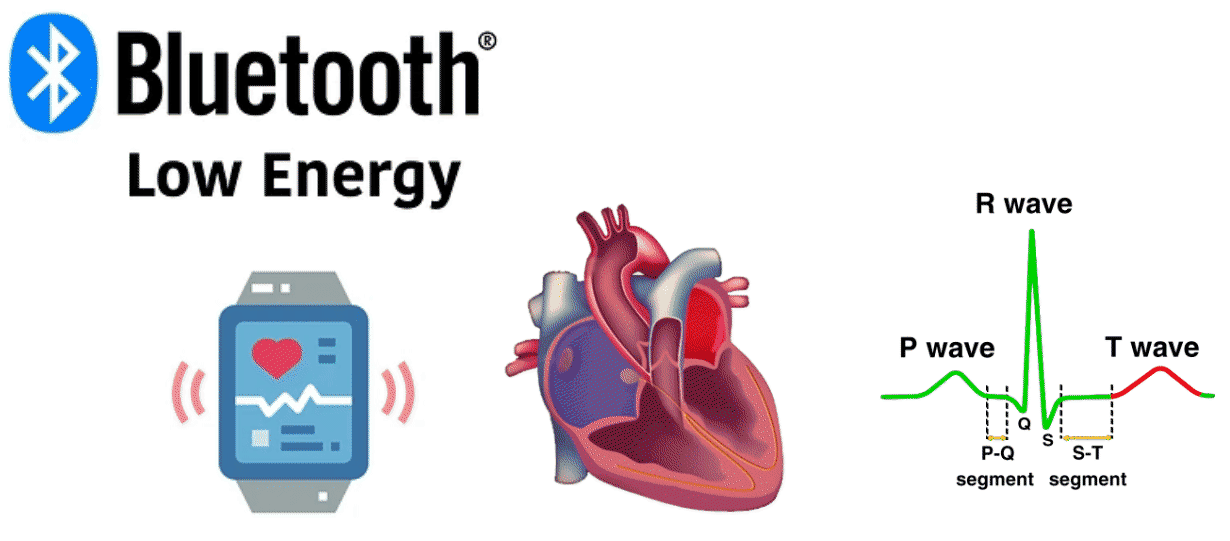
During my PhD, I also worked on a personal project to interact with bluetooth low energy (BLE) smart watches in Python. This was used to read the heart rate (bpm), systolic/diastolic blood pressure (mmHg) and SpO2 blood oxygen (%) with a live plot of real-time HR readings using gnuplot. I also used Python to perform data analysis on the data collected from the smart watch.
After leaving academia, one of the roles I decided to pursue was a Scientific Software Engineer at the Meteorological Office. For this role, I gave a presentation on the history, applications and good practices of scientific software engineering.

Ultimately I decided to embark on a career in data science instead. Nevertheless, the panel was very impressed with my application and noted that I had a good understanding of the importance of software quality, and awareness of the challenges of developing scientific software. I also demonstrated good examples of software development, especially in Python and a sensible approach to debugging code, including when working with other’s code.
I am experienced with data science and machine learning Python libraries (e.g Scikit-learn, Keras, Tensorflow) as well as data visualization software such as Tableau and Power BI.


As a freelance data scientist, I analysed instantaneous power consumption data of a large number of households with supervised machine learning models to identify various devices (e.g the TV or kettle) and classify when they are turned on and the occurrences/duration of their usage, to identify routines and the detection of anomalies. This data was provided by a particular company that aims to use ML and modelling with domestic electric appliances.

My journey at the Office for National Statistics
Throughout my tenure at the Office for National Statistics (ONS), I have made pivotal contributions to data science and analysis, specializing in the development of advanced statistical and machine learning models, designing analytical data pipelines, and crafting data visualizations to distil complex data insights. Key projects include devising sophisticated multilateral price indices for the treatment of alternative data sources, implementing novel machine learning methodologies in Python, and significantly enhancing the computational efficiency of data processes. Furthermore, my commitment to knowledge sharing has positioned me as a mentor to new team members and a key presenter in various organizational seminars.

Data Scientist in Reproducible Data Science and Analysis
In June 2021, I was employed as a Data Scientist at the Higher Executive Officer grade at the ONS within the Economics Statistics Group (ESG) and the Reproducible Data Science and Analysis (RDSA) team, formerly known as Emerging Platforms Delivery Support (EPDS).
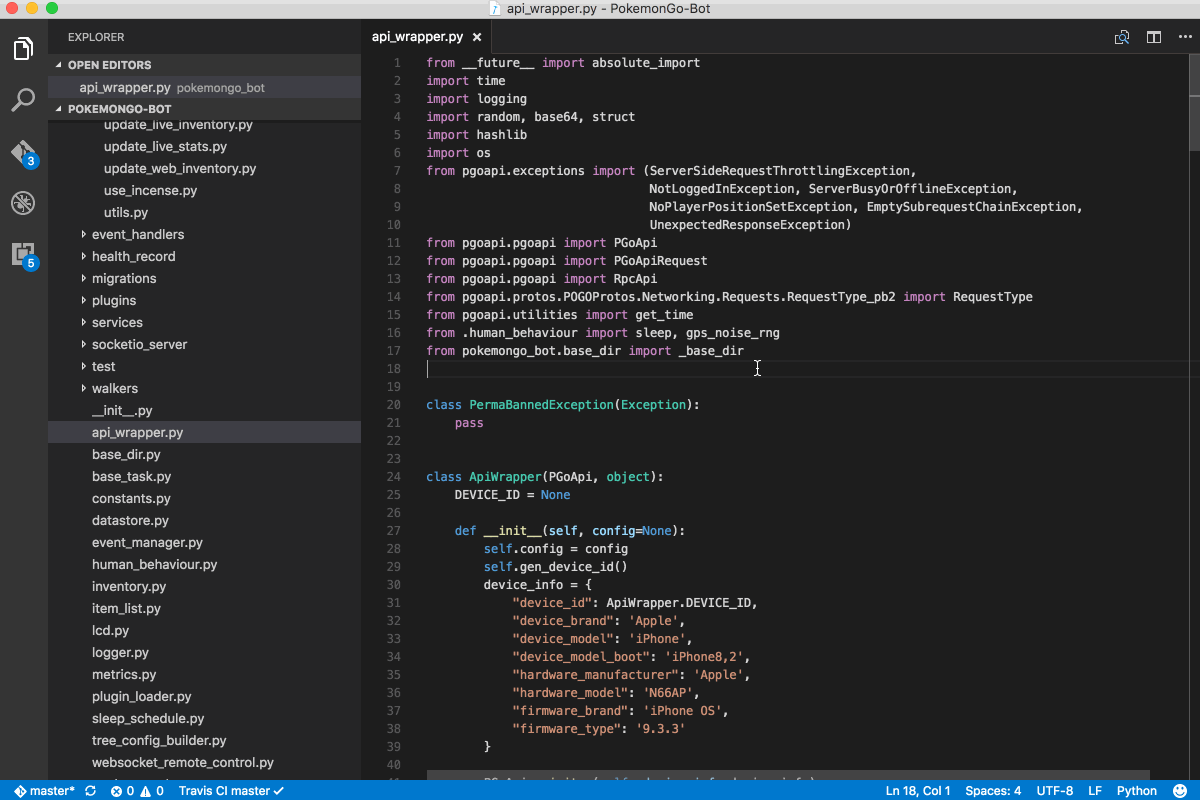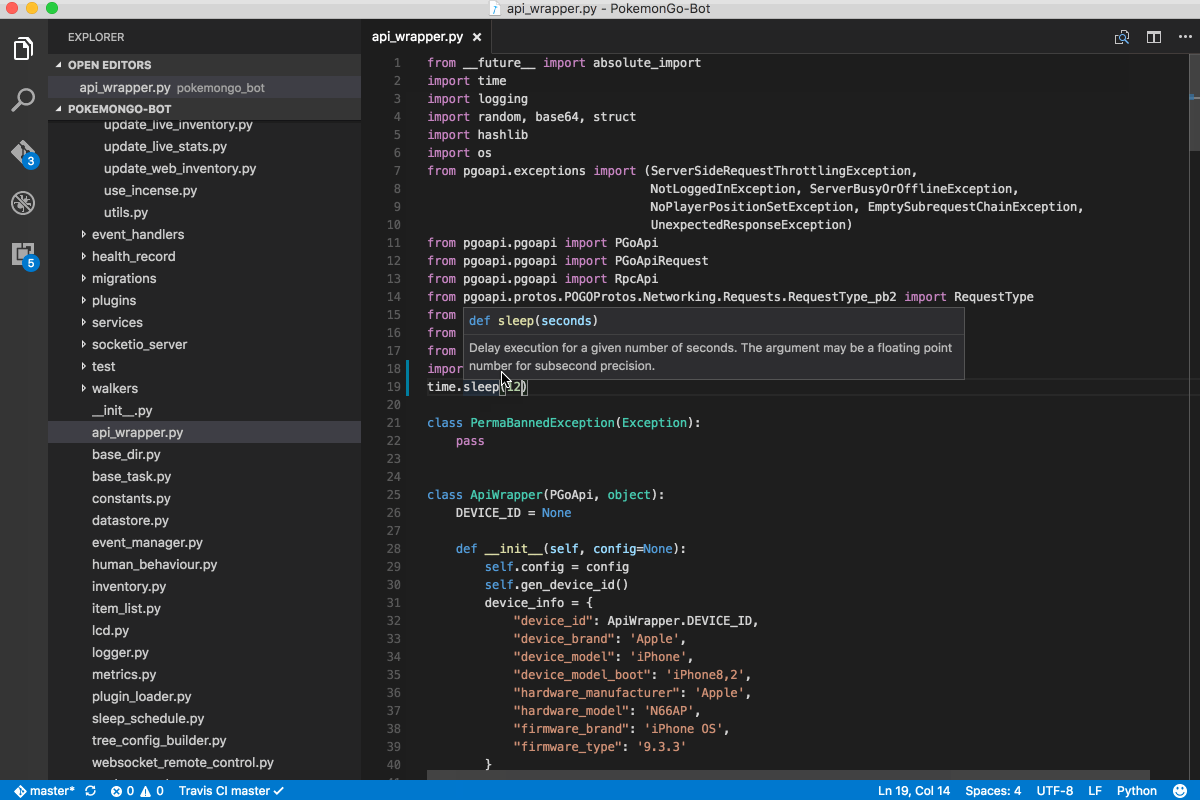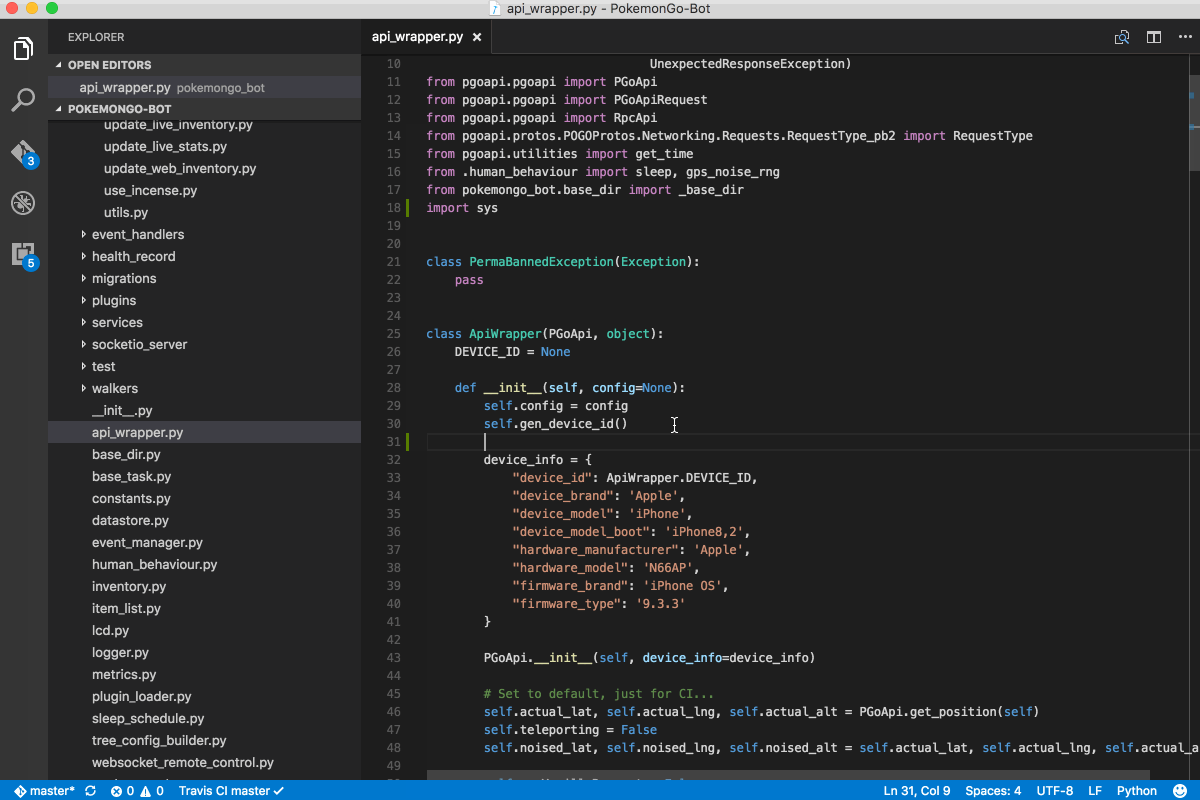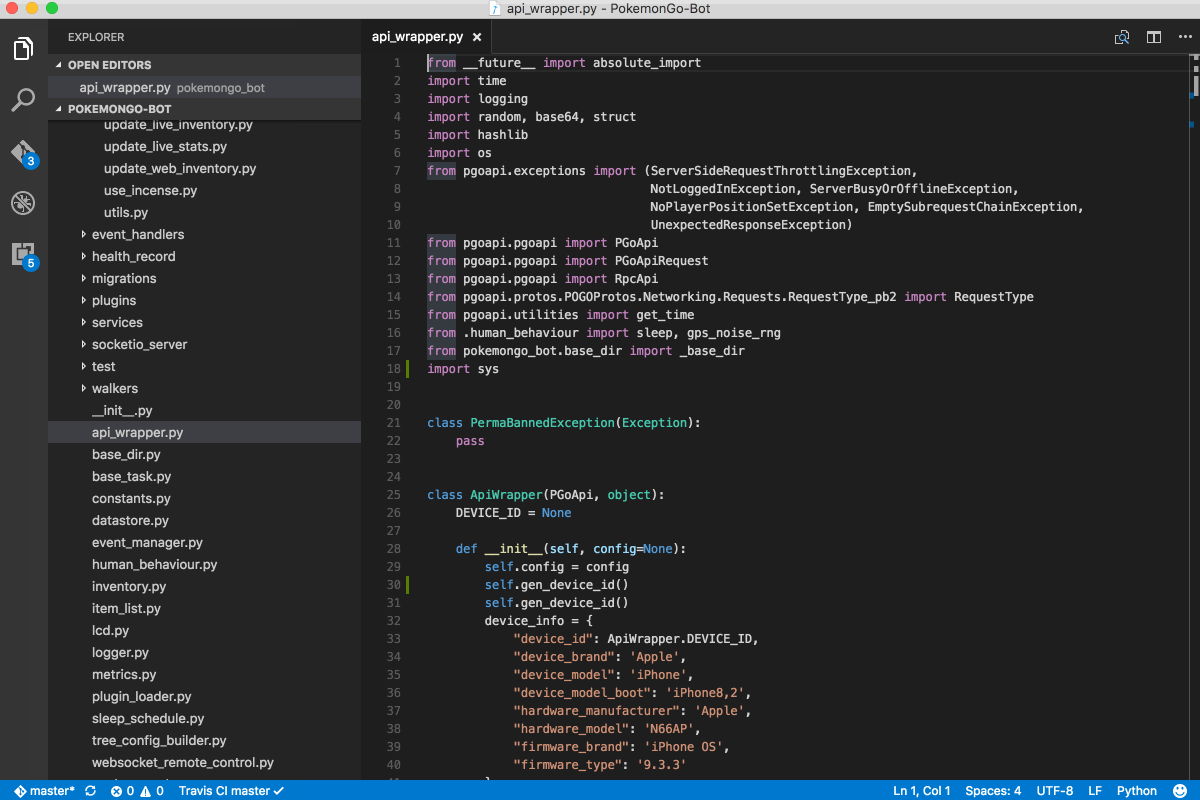
After only my second month at the ONS, I was a member of the induction team responsible for onboarding new starters and aiding or mentoring to new members of the team. My main work was researching and implementing multilateral price indices, using calculations and time series extension methods in Python. This work was as part of an ETL Reproducible Analytical Pipeline (RAP) on Cloudera with Apache Spark for the treatment of alternative data sources (scanner and web-scraped data) and new index methods which will be used to determine the consumer price index (CPI) in the future.
As part of the new index methods, I had been looking at mutlilateral methods which simultaneously make use of all data over a given time period. Their use for calculating temporal price indices is relatively new internationally, but these methods have been shown to have some desirable properties relative to their bilateral method counterparts, in that they account for new and disappearing products (to remain representative of the market) while also reducing the scale of chain-drift.
While working on building a data pipeline for the CPI, I made very significant contributions both to methodology and computational efficiency for the integration of alternative data sources. In my first few months, I led an investigation into a particular implicit hedonic multilateral index method known as the Time Product Dummy (TPD) method, which uses a log-linear price model with weighted least squares regression and expenditure shares as weights.
\[\begin{aligned} \ln p_i^{t} &= \alpha + \sum_{r=1}^T \delta^r D_i^{t,r} + \sum_{j=1}^{N-1}\gamma_j K_{i,j} + \epsilon_i^{t} \ , \\ s_i^{t} &= \frac{p_i^t q_i^t}{\sum_{j=1}^N p_j^t q_j^t} \ . \end{aligned}\]After noticing an error in the formulae and example workbooks produced for these methods and bringing this to the attention of the ONS, I worked closely with people from methodology on making sure we got all the technical details right.
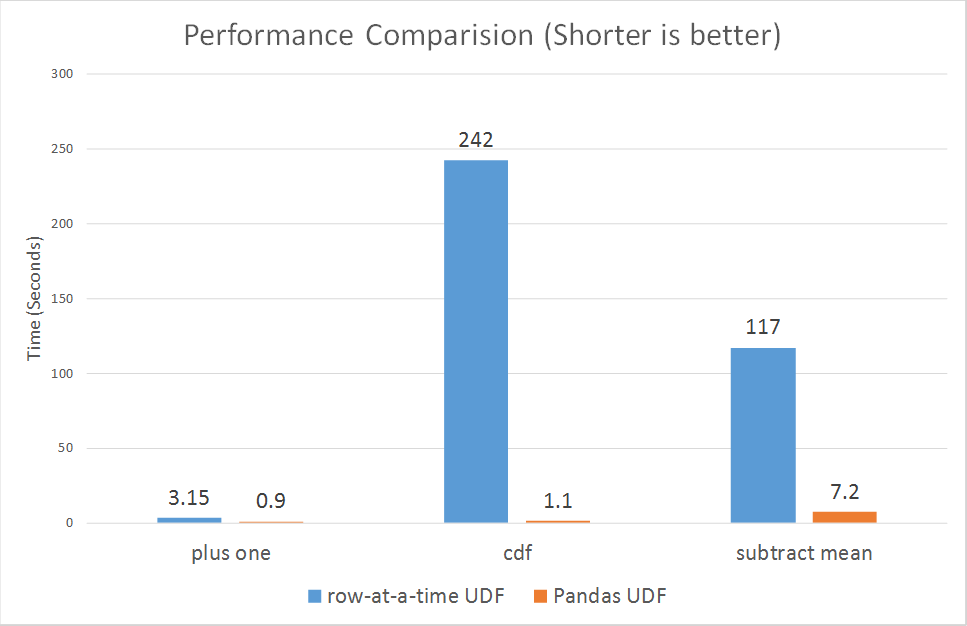
My first task was to implement the TPD method within the CPI pipeline using PySpark. Spark’s native ML library though powerful generally lacks many features, and is not suited for modelling on multiple groups or subsets of the data at once. The usual approach to use custom functions or transformations which are not part of the built-in functions provided by Spark’s standard library is to use a User Defined Function (UDF). However, the downside of this is they have performance issues, since they executed row-at-a-time and thus suffer from high serialization and invocation overhead.
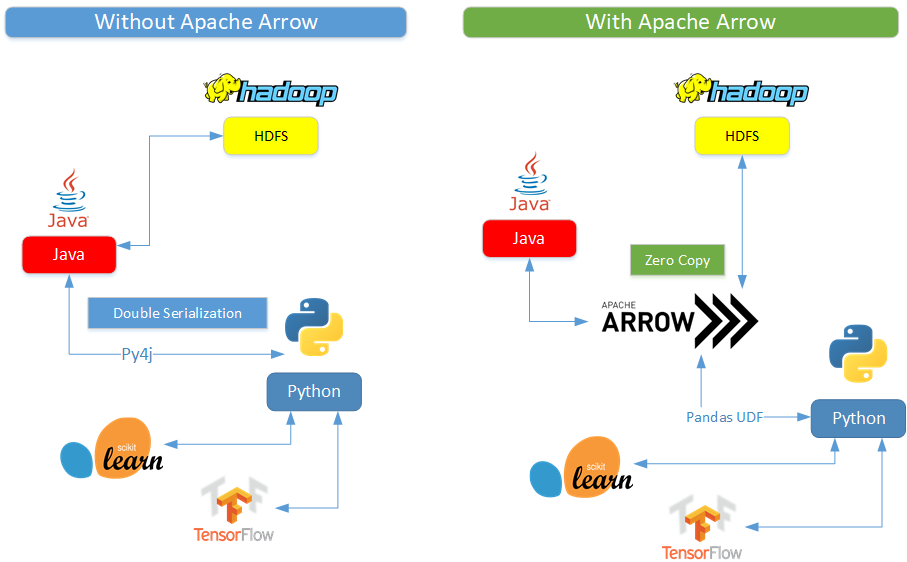
This led me toward discovering Pandas UDFs, which allow for vectorized operations on Big Data and increase performance by up to 100x compared to regular UDFs using Apache Arrow. They have since been implemented in various multilateral index methods and are an integral part of the CPI pipeline.
I also used the same ideas for the Time Dummy Hedonic (TDH) method, which is an explicit hedonic model similar to TPD, but also uses the item characteristics in the WLS regression model.
\[\begin{aligned} \ln p_i^{t} = \delta^0 + \sum_{r=1}^T \delta^r D_i^{t,r} + \sum_{k=1}^K \beta_k z_{i,k} + \epsilon_i^{t} \ . \end{aligned}\]After implementing the TPD and TDH methods, I turned my attention to another multilateral method known as Geary-Khamis (GK) and the usual method involves iteratively calculating the set of quality adjustment factors simultaneously with the price levels.
\[\begin{aligned} b_{n}&=\sum_{t=1}^{T}\left[\frac{q_{t n}}{q_{n}}\right]\left[\frac{p_{t n}}{P_{t}}\right] \ , \nonumber \\ P_{t}&=\frac{p^{t} \cdot q^{t}}{ \vec{b} \cdot q^{t}} \ . \end{aligned}\]I was able to independently research and implement a method solely based on matrix operations, which makes the method more efficient since it has vectorized operations which act on the entire data. I also refactored my code for TPD and TDH using matrix operations, which turned out to be more efficient and increased performance by up to 7x compared to standard statistical libraries. The Pandas UDFs were also applied to the time series extension methods for TPD, TDH, GK and another multilateral method known as GEKS.
In October 2021, after working closely with methodology on index numbers, I was invited to join the Index Numbers Expert Group (INEG) and the Data Science and High-performance computing (DaSH) expert group.
In November 2021, I delivered a presentation in a seminar to my team and deparment, to introduce the concept of Pandas UDFs. This turned out to be a success as I got good engagement and questions after the presentation, as well as interest from other parties in DaSH, to watch the recording and slides. I also presented a seminar aimed at people both little and extensive knowledge of the subjects, and a Jupyter Notebook of worked examples. I discussed this material with a computing specialist, and with their feedback have produced useful material with a full set of instructions and worked examples, which is accessible to a wider audience.
Senior Data scientist in the Data Science Campus
In March 2022, I joined the Data Science Campus at the ONS with a promotion to Senior Executive Officer and a permanent role in the civil service.

My first project was on the least cost index, which was published in May 2022. I played a significant role in researching and implementing the price index and aggregation methods, which was powered by a Python price index package which I created called PriceIndexCalc.
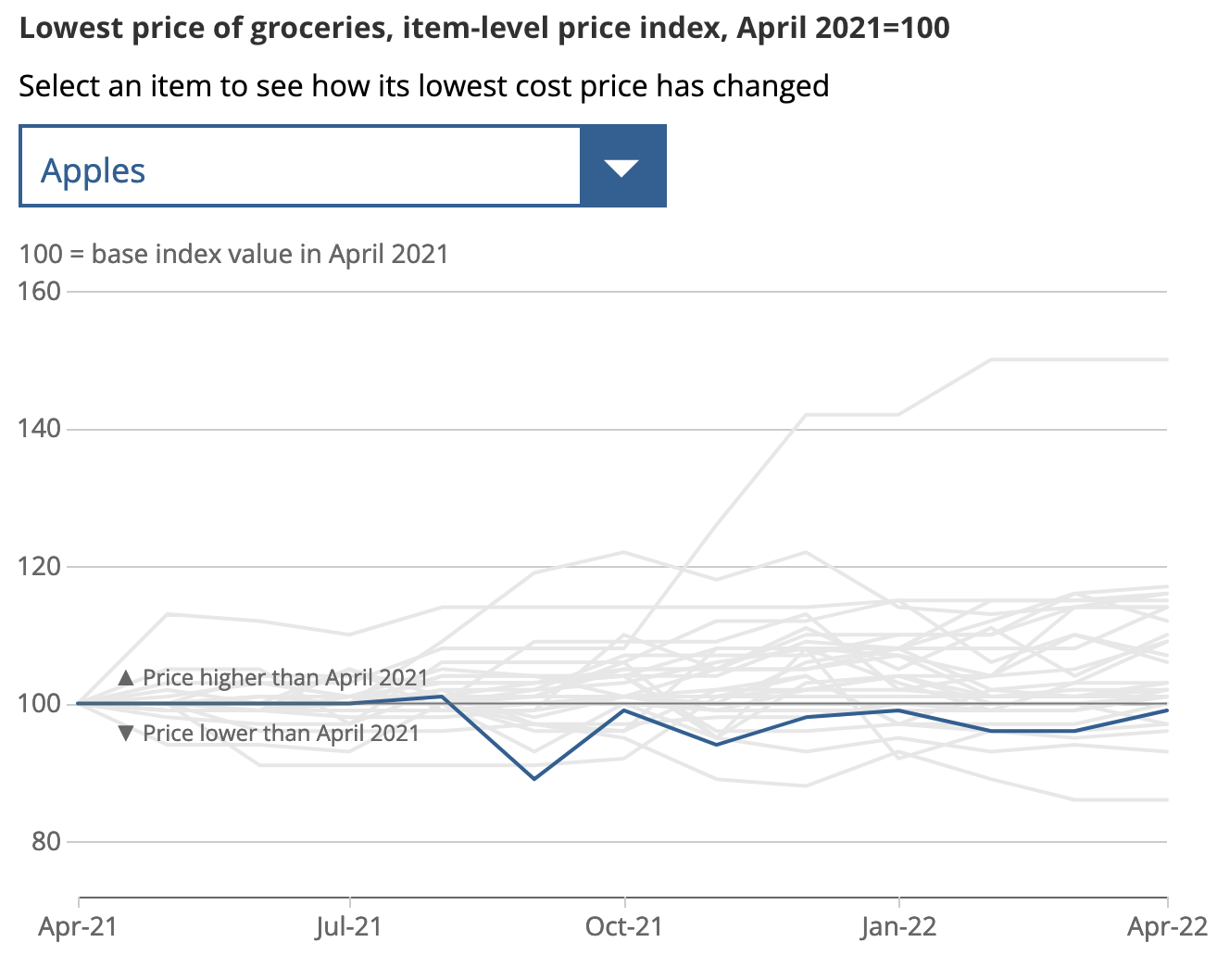
My package and work was used to track the prices over time of the lowest-cost grocery items for 30 products over multiple retailers, using web-scraped data and a data pipeline on the Google Cloud Platform. This analysis was conducted as part of the ONS’s current and future analytical work related to the cost of living.

In April 2022, I also joined the Data Access Platform Capability And Training Support (DAPCATS) as a mentor, where I have been helping other data scientists and analysts with their work and projects.
![]()
I also took part in the Spark at the ONS event hosted by DAPCATS and created for the launch of a new online book. This event was used to discuss various topics and resources related to Spark and Big Data, and I delivered a presentation titled Spark application debugging, tuning and optimization. For this talk, I discussed various tips and techniques to increase efficiency, identify bugs or bottlenecks that can cause Spark applications to be slow or fail, and tuning Spark parameters accordingly. This can help to reduce overall developer and compute time, costs for resources to run the Spark application or the environmental impact that comes with using unnecessary extra resources or having significantly longer runtimes.
In August 2022, I received the Recognition Award for outstanding collaboration and contribution to the ONS. I provided very important support to help another team to publish the Capital Stocks user guide article and the work has made the UK the only country to introduce such transparency. The process involved sharing their statistical production code in the ONS’s GitHub account and I dedicated my time to help them set up the initial account, and to upload the packages in GitHub as the team hadn’t experienced using this platform before. I also took the time to give them a very detailed walk through of how the platform works, and helped them by sharing tips and examples of good practice. My support enabled them to make their capital stocks statistical production system accessible and reproducible by all external users, helping them make the statistics more inclusive and introducing innovating platforms to help their users improve their analysis and budgetary forecasting.
In September 2022, I continued to work on a project to investigate the feasibility of using transparency declarations to improve intelligence on public sector expenditure and increase the quality of ONS public statistics. The declarations refer to expenditure data that local councils and central government bodies must publish to meet their transparency requirements. This work may also offer insights into the spatial distribution of public spending, which could be useful for policy agendas.
In October 2022, I became a founding member of the ONS Data Science Network, a new cross-departmental group that promotes data science events and training across the organization. The network also provides a forum for data scientists and analysts to discuss and share ideas on data science and analysis, and to promote the use of data science and analysis. The network consists of founding members from the Reproducible Data Science and Analysis (RDSA), Methodology and Quality Directorate (MQD), and Data Science Campus (DSC).
In November 2022, I had a one-on-one chat with Professor Sir Ian Diamond, the National Statistician and head of the ONS, about ways to improve transparency for statistics. We discussed the importance of releasing code for scrutiny and learning purposes, as well as the challenges that prevent people from releasing code. We also talked about the potential for the ONS Data Science Network to promote code quality for data science projects across the organization. Additionally, we discussed the importance of data visualization and communication in transparency and the ONS’s efforts to improve in this area.
In December 2022, I received the Recognition Award again for outstanding collaboration and contribution to the ONS. I helped another team in a different department who recently migrated their systems and team of new developers to GCP. They encountered issues getting things set up with the on-prem laptop and GCP, largely due to niche ONS system restrictions which made it difficult to find resources on the internet to solve them. I generously shared my knowledge and expertise, which saved the team a lot of time and helped them gain a deeper understanding of the topic.
In May 2023, despite leaving the ONS in January of the same year, I was honored with another Recognition Award for the impactful contribution I had made in establishing a cross-ONS network of data scientists during my time at the organization. Displaying initiative, I set up a project management tool to handle different aspects of the network and its prospective deliverables. Moreover, I created a dedicated communication channel and a network inbox, both of which were critical for effective communication within the network. My proactive role in laying the foundation for the network was acknowledged as instrumental in creating a thriving environment where data scientists across the ONS could collaborate and learn. This achievement not only acknowledges my contributions to the data science community within the ONS but also underscores the importance of fostering collaboration and community in the ever-evolving field of data science.
My journey at Quantexa
My role as a Data Engineer at Quantexa has been a deep and evolving journey into large-scale data engineering, platform reliability, and DataOps. Working within Research and Development, I have had the opportunity to push the boundaries of big data systems that support complex analytics and entity resolution at scale. This journey has been defined by perseverance, ambition, teamwork, and accountability—principles that align closely with Quantexa’s core values and with how I approach engineering more broadly.
From the outset, my focus has been on building systems that are not only technically sophisticated, but operationally dependable. Whether optimising workflows with Python and Scala, strengthening orchestration with Airflow, or identifying and mitigating systemic failure modes in distributed environments, I have consistently sought to deliver work that has lasting impact. I place strong emphasis on inclusivity and shared ownership, fostering environments where knowledge is accessible and teams can grow collectively rather than relying on a few individuals. Accountability and continuous improvement are central to how I work, supported by feedback, reflection, and high personal standards.

Data Engineer in Research and Development (R&D)
I joined Quantexa in January 2023 as a Data Engineer in Research and Development, working in a fast-paced environment focused on large-scale data processing, analytics, and dynamic entity resolution. From the outset, my role sat at the intersection of data engineering, platform reliability, and applied research, contributing to systems designed to support complex analytical use cases across multiple industries. What drew me to the role was not just the technical challenge, but the emphasis on contextual understanding and the belief that better decisions emerge from well-designed, well-governed data systems.
My work during this phase was highly dynamic and impactful, encompassing the development, testing, and documentation of data engineering tools and best practices that support production deployments. A significant proportion of my contributions involved pragmatic, high-leverage engineering in the critical path: fast, targeted fixes to keep environments stable and releases moving. These changes were often small in isolation—such as correcting metadata wiring, safely reverting problematic schema or configuration changes, and preserving downstream correctness under release pressure—but high impact in practice. This required careful reasoning about schemas, configuration, and how changes propagate through distributed data workflows.
Alongside this work, I rapidly expanded my technical breadth. Although Scala was relatively new to me when I joined, I invested heavily in mastering it as a core language for large-scale data processing. This translated into tangible contributions that influenced sprint delivery, code quality, and performance optimisation, complementing my existing experience with Python and Java.
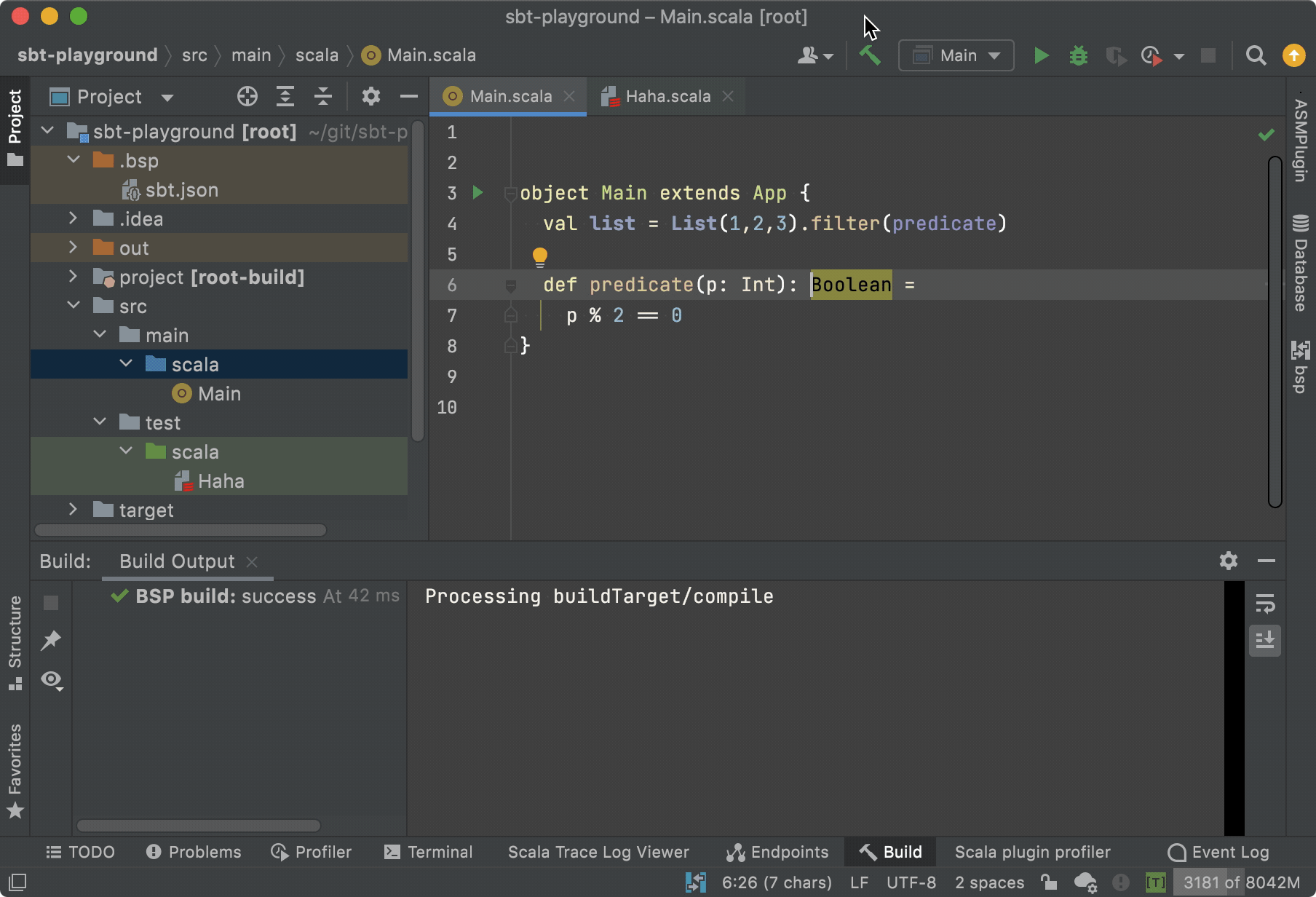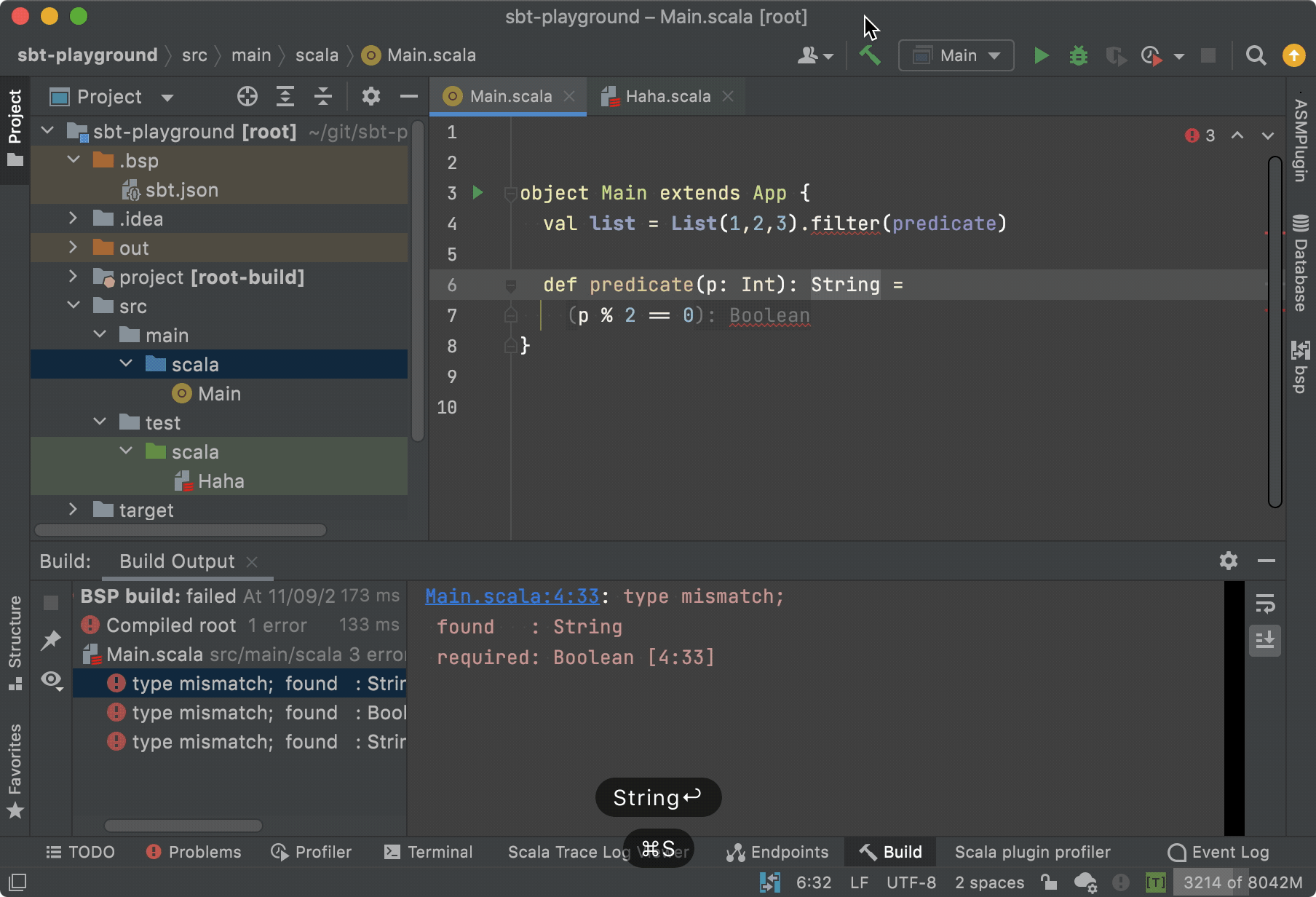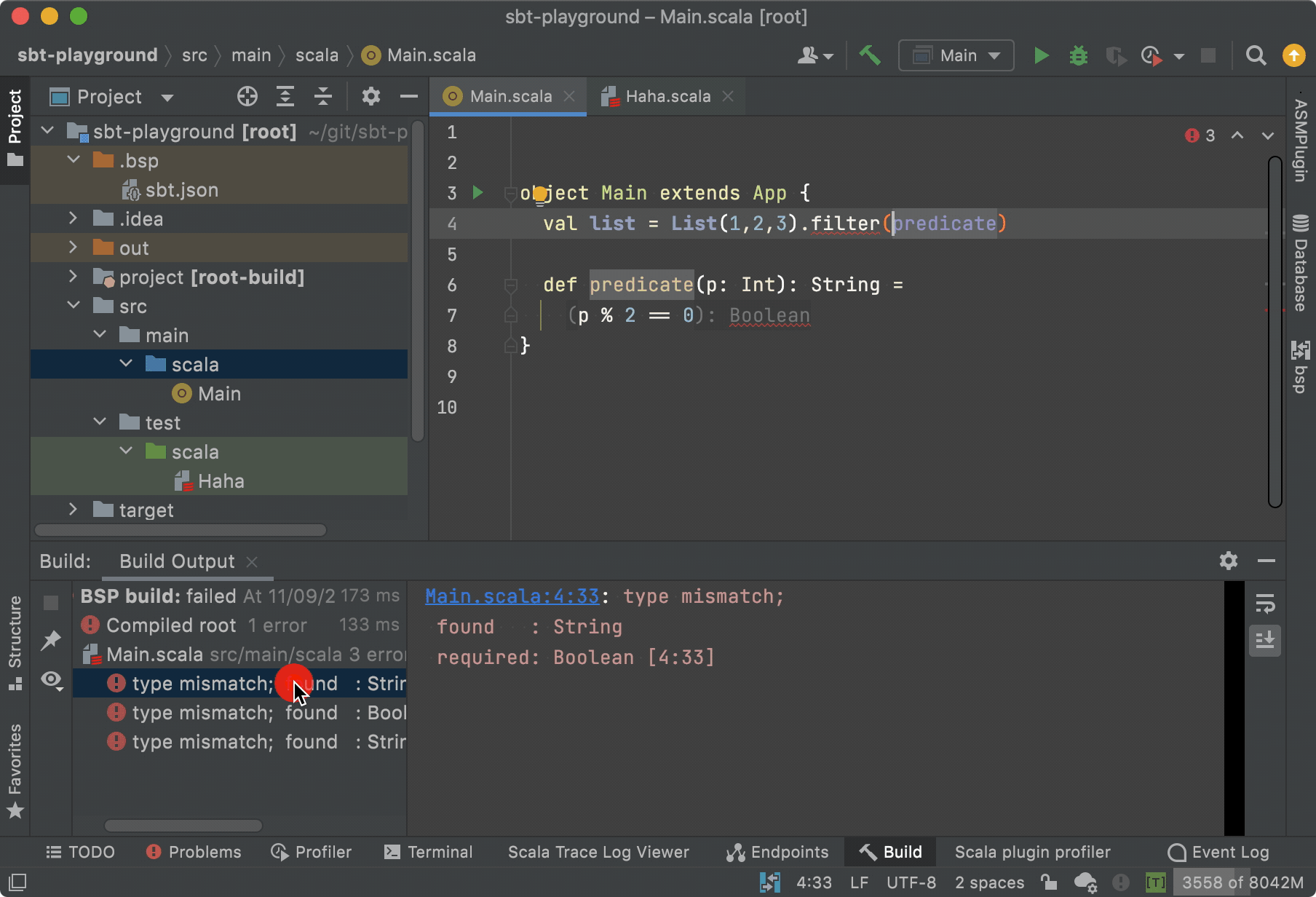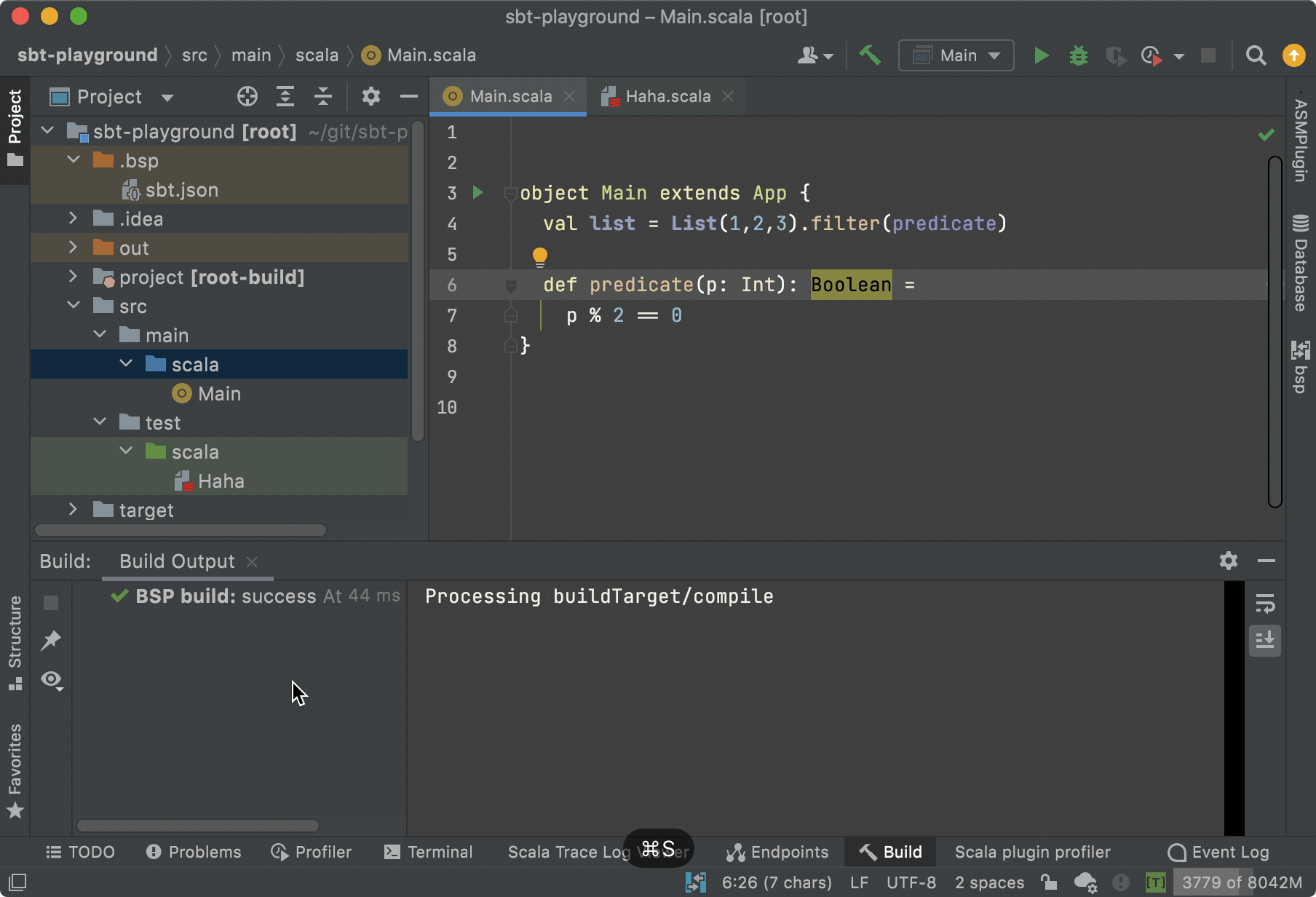
My broader knowledge of big data technologies—particularly Spark, Hadoop, and Elasticsearch—became increasingly central to defining and reinforcing best practices across the engineering organisation. Working across both cloud and on-premise environments, I supported the delivery of efficient, reliable solutions spanning ETL pipelines, data cleansing, parsing and standardisation, as well as data classification and entity extraction and resolution.

Stakeholder engagement was an important part of this role. I worked closely with delivery teams and partners to ensure that data workflows met real operational needs, balancing correctness, performance, and maintainability. This collaboration helped ensure that engineering decisions translated into reliable outcomes in production.

A significant milestone during this period was achieving a 97% score in the Quantexa Academy, earning the title of Quantexa Certified Data Engineer. This deepened my understanding of the technology stack and internal practices, and I actively supported other Academy participants, contributing to a collaborative learning culture within the team.
Senior Data Engineer in Research and Development (R&D)
In October 2024, I was promoted to Senior Data Engineer within Quantexa’s Research and Development division. In this role, my responsibilities expanded to leading complex data engineering initiatives and contributing to architectural decisions across the data platform. My work focuses on designing, developing, and optimising scalable pipelines that support large-scale data integration, advanced analytics, and entity resolution, using technologies such as Airflow, Spark, and cloud-native infrastructure. A strong emphasis of this role is on automation, performance, and infrastructure efficiency.
A major highlight of this period was spearheading the implementation of dynamic, configuration-driven Directed Acyclic Graphs (DAGs) and autoscaling in Airflow. This work significantly improved scalability and resource utilisation while making pipeline configuration more accessible and consistent across teams. It also laid the foundation for more standardised infrastructure practices and reduced the operational overhead associated with managing complex batch workflows.
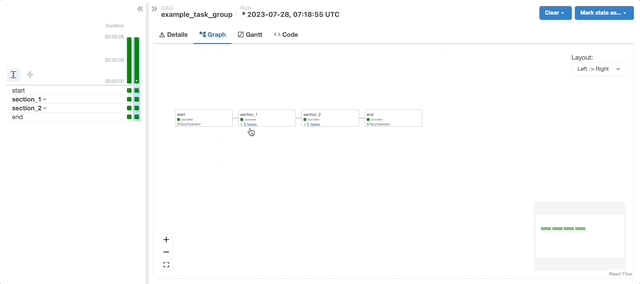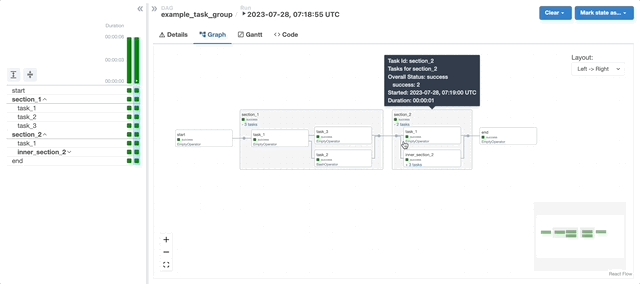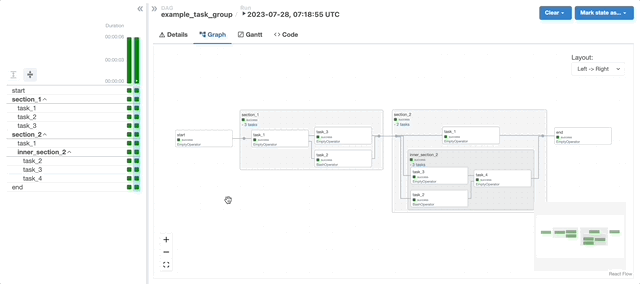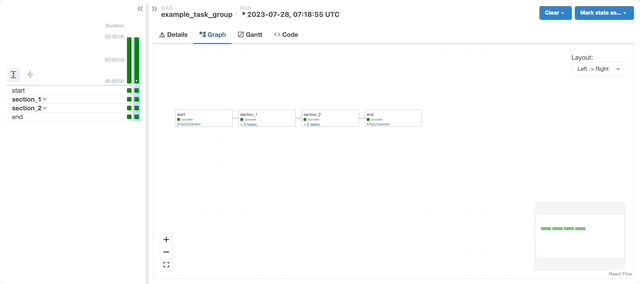
As my scope increased, my work shifted increasingly toward operational reliability and release correctness across end-to-end data pipelines. Rather than treating failures as isolated incidents, I focused on identifying systemic causes such as shared state, concurrency effects, retry semantics, and resource pressure in distributed execution. This required deep engagement with Airflow for orchestration and Spark running on cloud-native platforms, as well as careful analysis of failure modes that only surface at scale.
A major and recurring theme in my work has been incident response combined with deep root-cause analysis. I regularly investigated production-impacting failures where jobs degraded from minutes to hours or aborted entirely due to transient errors, timeouts, or infrastructure instability. Instead of relying on manual reruns, I worked to classify failure patterns, improve observability, and introduce safer execution behaviours so that pipelines could withstand faults without constant human intervention.
Over time, this reliability work converged into taking on a broader DataOps function. This role stretches beyond building pipelines to ensuring that the entire data lifecycle is reliable, observable, and increasingly automated. It involves running and supporting daily operations—scheduled ETLs, batch processing, and downstream reporting—while simultaneously designing processes that scale and can be made self-service for others. The balance has been between immediate operational stability and longer-term structural improvements that reduce operational load over time.
In parallel, I took on the role of DevProd Liaison for the DEAD (Data Engineering and Architecture Development) area and the wider Applications group. This role involves coordinating and driving Developer Productivity initiatives across multiple teams, with a focus on reducing build and CI friction, improving pipeline reliability, and establishing consistent tooling across repositories. As this liaison role evolves, additional workstreams and cross-team initiatives are being added to ensure improvements are tracked, visible, and consistently delivered across the Applications landscape.
One of my flagship contributions in this area has been architecting self-service batch operations, enabling teams to safely request and execute workloads through structured workflows with clear approvals, validation, and execution summaries. This has reduced ambiguity around what ran, where it ran, and with which configuration, while tightening feedback loops and improving traceability.
Mentorship has become a meaningful and rewarding part of my role. I work closely with junior engineers through code reviews, design discussions, and hands-on guidance, particularly around distributed systems, Scala, and Python. I place strong emphasis on clarity, shared understanding, and good engineering habits, helping others grow while maintaining high standards across large-scale data systems.
Innovation remains central to my work. I developed a dynamic DAG generator that allows ETL pipelines to be defined directly from configuration files, significantly reducing friction when creating or modifying workflows. My longer-term vision is to evolve this into a more visual, user-friendly interface that empowers data engineering teams to design, validate, and deploy pipelines without needing deep familiarity with orchestration internals. This reflects a broader commitment to democratising complex infrastructure rather than concentrating knowledge in a few individuals.
Another important aspect of my work is bridging across stakeholders. Different teams depend on reliable data workflows, and part of my responsibility is to ensure their needs are met consistently despite the complexity of the underlying systems. This has involved formalising expectations around data refreshes, reporting, and integration points, reducing friction in how requests are handled, and making operational behaviour more predictable and transparent.
Alongside my technical work, I am a strong advocate for neurodiversity and inclusive engineering practices, particularly for ADHD and dyslexic perspectives. I bring this into my work through clear documentation, accessible resources, and structured processes that reduce unnecessary cognitive load, helping ensure that all team members can contribute effectively.
As I continue my journey, I remain focused on building systems that are robust, accessible, and impactful, and on aligning deep technical work with the broader mission of delivering actionable insights through contextualised data.